There is a debate raging at the moment between different types of clouds hence I thought I'd stick my oar in. First, let's clear up some simple concepts:-
What is cloud?
Cloud computing is simply a term used to describe the evolution of a multitude of activities in IT from a product to a utility service world. These activities occur across the computing stack.
These activities are evolving because they've become widespread and well defined enough to be suitable for utility provision, the technology to achieve this utility provision exists, the concept of utility provision is widespread and there has been a sea-change in business attitude i.e. a willingness to accept these activities as being a cost of doing business and commodity-like.
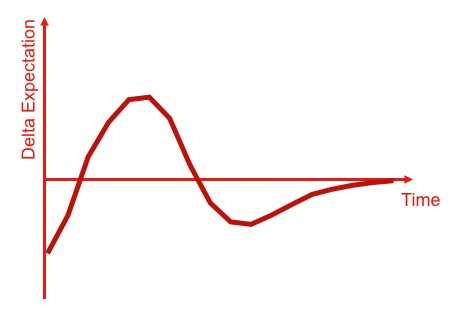
There is nothing special about this evolution, it's bog standard and many activities in many industries have undergone this change. During this change, the activities are moving from one model to another which creates a specific set of risks (both real and perceived) around trust in the new providers, transparency, governance issues and concerns over security of supply. There are other risks (including outsourcing and disruption risks) but these are irrelevant for the specific question of private vs enterprise clouds. Nevertheless, all of these "risks" help increase inertia to the change. For clarity's sake, I've summarised this evolution in figure 1.
Figure 1 - Lifecycle and Risk.
(click on image for larger size)

Why private clouds?
Private clouds (where the service is dedicated i.e. "private" to a specific consumer) are generally used as part of a hybrid strategy which combines multiple public sources with a private source. The purpose of a hybrid strategy is simply to mitigate transitional risks (concerns over governance such as data governance, trust etc). This is a normal supply chain management tactic and occurs frequently with this type of evolution. Even within the electricity industry you can find a plethora of hybrid examples in the early days of formation of national grids.
Fundamentally, a hybrid strategy mitigates risk but incurs the costs of both lesser economies of scale and additional resource focus when compared to a pure public play. It's a simple trade-off between benefits and risks which can often be justified for a time.
Why Enterprise Clouds?
Enterprise clouds need a bit more explaining and to understand why they exist we first have to start with architecture. To keep things really simple, I'm going to focus on infrastructure.
As per above, the use of computing infrastructure has undergone a typical evolution from innovation to commodity forms and more recently the appearance of utility services. In the earlier stages of evolution, the solution to architectural problems was bound to the physical machine. Scaling was solved through buying "a bigger machine" i.e. Scale-Up whereas resilience involved hot-swap components, multiple PSUs and other redundant physical elements (the N+1 model). This was essential because of the long lead time for replacement of any physical machine i.e. there existed a high MTTR (mean time to recovery) for a physical server. Applications therefore developed on the assumption of ever bigger and ever more resilient machines. These architectures spread (specific sets of knowledge behave just like activities) and became best practice.
As computing infrastructure became commodity-like, novel system architectures such as Scale-Out (aka as horizontal scaling) developed. These solved scaling by distributing the application over many more smaller and standardized machines. The new architectural solution was therefore "buy more machines" and not "buy a bigger machine". This scale-out architecture rapidly spread as infrastructure became more generally accepted as a commodity.
As we entered the utility phase, infrastructure has in effect become code – that is, we can create and remove virtual infrastructure through API calls. The MTTR of a virtual machine provided through a utility service is inherently lower than its physical counterpart and novel architectures called "design for failure" have emerged that exploit this. The technique involves monitoring a distributed system and then simply adding new virtual machines when needed.
In the cloud world application scaling and resilience are solved with software whereas in legacy it was often solved by physical means. This is a huge difference and I've summarized these concepts in figure 2.
Figure 2 - Evolution of Architectures
(click on image for larger size)

By necessity, public cloud infrastructure is based upon volume operations – it is a utility business after all. Virtual compute resources come in a range of standard sizes for that provider and are based upon low cost commodity hardware. These virtual resources are typically less resilient than their top of the line physical enterprise class counterpart but naturally they are vastly cheaper.
It should be noted that a ‘design for failure’ approach can take advantage of these low cost components to create a far higher level of resilience at any given price point through software.
By way of example, the general rule of thumb is that each 9 roughly doubles the physical cost. Hence let's take a scenario of a base machine designed to give a 99% up-time with a machine designed to provide 99.9% uptime costing twice the amount etc.
In the above scenario, using four base machines in a distributed architecture provides a theoretical up-time of 99.999999% though naturally it will suffer periods of degraded performance due to single, dual or triple machine failure. In a utility computing environment, this impact is negligible due to the low MTTR of creating new virtual machines and in such as case you have a low cost environment (4x base unit), high level of resilience for total failure (1 in 100 million) and fast recovery for periods of degraded performance due to the low MTTR.
Now compare this to a single physical machine (ignoring all scaling, network and persistence issues etc). The equivalent physical machine would be 16x more costly (assuming the 2x rule holds) and in the rare situation that complete system failure occurred, the MTTR would be high. In reality, MTTR would be high for all its components unless spares were kept.
Now for reasons of brevity, I'm grossly simplifying the problem and taking a range of liberties with concepts but the principle of using vast numbers of cheap components and providing resilience in software is generally sound. We've seen many examples of this including RAID. These cloud architectures are no different except they extend the concept to the virtual machine itself.
The critical point to understand is that these two extremes of architecture have fundamentally different models based upon the differences in the underlying components i.e. the architectural practice co-evolved with the activity. The cloud model is based upon volume operation provision of commodity good enough components with application architectures exploiting this through scale-out and design for failure. Now in the following figure I've tried to highlight this difference by providing a greyscale comparison between a traditional data centre and a public cloud on a number of criteria.
Figure 3 - Data Centre vs Cloud.
(click on image for larger size)

OK, now we have the basics let's look at the concept of Enterprise Cloud. The principle origin of this idea is that whilst many Enterprises find utility pricing models desirable, there is a problem when shifting legacy environments to the cloud. Now when companies talk of shifting an ERP system to the cloud they often mean replacing own infrastructure with utility provided infrastructure. The problem is that those legacy environments often use architectures based upon principles of scale-up and N+1 and infrastructure provided on a utility basis doesn't confirm to these high levels of individual machine resilience. The problem is simply people are trying to shift applications built with best architectural practice for product based infrastructure to a world where infrastructure is a utility which has its own but different best practice. It's not that legacy is wrong, it's just that in this case legacy means built with best practice for a product world and that practice is no longer relevant.
At which point the company has two options; either re-architect to take advantage of the volume operations through scale-out and design for failure concepts or demand for higher level resilient virtual infrastructure i.e. try and make the new world act like the old world.
This is where Enterprise Cloud comes in. It's like cloud but the virtual infrastructure has higher levels of resilience but at a high cost when compared to using cheap components in a distributed fashion. So why Enterprise cloud? The core reason behind Enterprise Cloud is often to avoid any transitional costs of redesigning architecture i.e. it's principally about reducing disruption risks (including previous investment and political capital) by making the switch to a utility provider relatively painless. However, this ease comes at a hefty operational penalty. The real gotcha' is those transitional costs for redesign increase over time as the system itself becomes more interconnected and used.
In principle, Enterprise Clouds are used to minimise disruptional risks but they will be ultimately subject to a transition to the new architecture because of high operational costs. There are other reasons for an "Enterprise Class" cloud but most of these, such as where data resides, can also be provided by using a "Private" cloud that is built using commodity components until suitable "Public" clouds are available.
The different economic models is what separates out private / public compute utilities from enterprise clouds, I've highlighted this on the greyscale in figure 4. Actually, I prefer to use the original term virtual data centre rather than enterprise cloud because that's ultimately what we're talking about.
Figure 4 - Enterprise vs Private Cloud.
(click on image for larger size)

Do Enterprise Clouds have a future? Sort of, but they'll ultimately & quickly tend towards niche (specific classes of SLAs, network speeds, security requirements etc). Their role is principally in mitigating disruption risks but the transitional costs they seek to avoid can only be done at an increasing operational penalty. It should be noted that there is a specific tactic where an enterprise cloud can have a particularly beneficial role: the "sweating" of an existing legacy system prior to switching to a SaaS provider (i.e. "dumping" the legacy). In most cases, Enterprise clouds will become an expensive folly.
Do Private Clouds have a future? Yes, they have a medium term (i.e. next few years) benefit in mitigating transitional risks (such as issues over data governance) through the use of a commodity based model. However, be careful what you're building and remember the impact of private clouds will diminish as the public markets develop. I say "be careful what you're building" but in practice this means don't build. The vast majority of companies lack the skills and management capability necessary and though you're trying to build a "commodity" based private cloud, the chances are you'll end up with some very "enterprise cloud" like.
Do Public Clouds have a future? Absolutely, this is the long term economic model and will become the dominant mechanisms. Public utilities should also encourage clearing houses, exchanges and brokerages to form.
Last thing, I said I would focus on infrastructure to keep things simple. The rules change when we move up the computing stack ... but that's another post, another day.
--- 8th February 2016
Note to self.
Five years later and ... oh, my past self would not want to know.
People are still building private clouds and trying to push enterprise class cloud despite the obviousness of the changes. The whole co-evolution of practice finally became firmly established as DevOps but has gone a little bit out of control in terms of making somewhat grand claims of cultural changes. The points of inertia and the overstating of risks continues in corporations but we're finally getting through that point in the punctuated equilibrium that this will all get washed away.
Overall, it has been a torrid journey. Many are still confused on basic concepts such as the change of practice with activities. We're still having this discussion today! I have to caution that legacy isn't flawed as much as built with best practice for a product world. Many are trying to "create" new paradigm shifts in order to re-establish flagging business models by "having another go". In many cases, the strategic play of many former IT giants has been next to hopeless. There's quite a list of well known names circling the spiral of death by cost cutting to restore profitability whilst the underlying revenues are in decline.
It has become plainly clear that the level of blindness to the environment (i.e. poor situational awareness) is incredibly high in most corporations at the executive level and far worse than I could have possibly anticipated. Inertia will always need to be managed but that such companies failed to manage predictable changes with so much warning is ... stunning.
--- 8th February 2016
Note to self.
Five years later and ... oh, my past self would not want to know.
People are still building private clouds and trying to push enterprise class cloud despite the obviousness of the changes. The whole co-evolution of practice finally became firmly established as DevOps but has gone a little bit out of control in terms of making somewhat grand claims of cultural changes. The points of inertia and the overstating of risks continues in corporations but we're finally getting through that point in the punctuated equilibrium that this will all get washed away.
Overall, it has been a torrid journey. Many are still confused on basic concepts such as the change of practice with activities. We're still having this discussion today! I have to caution that legacy isn't flawed as much as built with best practice for a product world. Many are trying to "create" new paradigm shifts in order to re-establish flagging business models by "having another go". In many cases, the strategic play of many former IT giants has been next to hopeless. There's quite a list of well known names circling the spiral of death by cost cutting to restore profitability whilst the underlying revenues are in decline.
It has become plainly clear that the level of blindness to the environment (i.e. poor situational awareness) is incredibly high in most corporations at the executive level and far worse than I could have possibly anticipated. Inertia will always need to be managed but that such companies failed to manage predictable changes with so much warning is ... stunning.